
loudness [ˈlaʊdnɪs] n (see adj): forza; fragorosità; rumorosità, chiassosità
Un altro dei concetti oggi sulla bocca (e nelle orecchie) di tutti noi, produttori e fruitori di musica ed audio in generale, è quello di “loudness”.
Per quanto una terminologia italiana equivalente tutto sommato esista (“loud” e “quiet” possiamo tranquillamente tradurli col nostro “forte” e “piano”), in ambito tecnico il concetto di loudness è andato via via nel tempo arricchendosi di significato specifico, per cui oggi è cosa comune utilizzare termine inglese in modo universale.
Prima di addentrarvi nella lettura, vi consiglio in maniera propedeutica (se già non lo avete fatto) quest’altro mio articolo, che ci aiuterà a parlare la stessa lingua.
Il loudness si può descrivere come quell’attributo della sensazione uditiva in base al quale diversi suoni possono essere soggettivamente collocati in un ordine che va dal più “piano” al più “forte”.
Per quanto un suono possa già essere caratterizzato in maniera assoluta ed oggettiva in termini, diciamo così, “volumetrici” (tramite il livello di pressione sonora SPL ad esempio), il loudness è qualcosa di più complesso, perché coinvolge la fisiologia umana e come l’orecchio dell’essere umano risponde allo stimolo uditivo. Il loudness dipenderà quindi sicuramente dall’effettivo livello di intensità sonora “pura”, ma anche dalla frequenza, dal contenuto armonico, dalla durata del suono stesso, e finanche dalle caratteristiche fisiologiche dell’ascoltatore.
Dobbiamo agli scienziati statunitensi Fletcher e Munson il primo studio organico e completo, negli anni ’30 del secolo scorso, di come l’orecchio umano percepisca in termini di “loudness” suoni a varie frequenze ed intensità. Il loro lavoro può sintetizzarsi nelle “curve di Fletcher & Munson”, che descrivono la risposta in frequenza della percezione sonora nell’uomo nel campo udibile (da 20 a 20.000Hz), e che attraverso perfezionamenti successivi sono divenute le attuali curve “Equal-Loudness” universalmente riconosciute secondo le norme unificate ISO 226:2003:

Thanks to Lindosland at en.wikipedia [Public domain], via Wikimedia Commons
La quantità di informazioni che tale diagramma ci regala è ragguardevole.
Ogni curva (le chiamiamo curve isofoniche, ovvero curve lungo le quali la sensazione uditiva di loudness è costante) rappresenta per così dire la “risposta in frequenza” del sistema-uomo.
Chiamiamo Phon il livello di pressione sonora (in dB SPL) di un suono ad una determinata frequenza che produce la stessa sensazione di loudness di un suono a 1000Hz.
Difficile? Non tanto, dai. Vedetela così: un suono a 60dB / 1000Hz, avrà un loudness di 60 Phon (per definizione). Ma per avere altrettanta sensazione di loudness (ovvero i nostri 60 Phon), ad esempio a 100Hz ci servirà una pressione sonora decisamente maggiore, quasi 80dB SPL.
Vista al contrario, se a 50Hz per avere una sensazione di loudness pari a 80 Phon ci servono oltre 100dB SPL, la stessa pressione sonora a 3000Hz sarà sufficiente ad assordarci.
Significa che il nostro orecchio è decisamente meno sensibile alle basse frequenze che non alle medie (dopotutto, vi siete mai chiesti perché un bassista gira con amplificatori da 500W, mentre al chitarrista basta un combo da 50W per spettinare gli ascoltatori?)
Osservando la forma delle curve, ricaviamo che la sensibilità è massima fra i 1000 ed i 5000Hz, per poi decrescere nuovamente al salire della frequenza.
Non solo. Noterete che le curve isofoniche tendono ad “appiattirsi” man mano che si sale di loudness (e quindi a valori di Phon più elevati). Vi dice niente? Non vi fa pensare al fatto che a volumi più alti la musica suona “soggettivamente” meglio (louder-sounds-better, dicono gli anglofoni)? Proprio così… una percezione migliore dei range basso ed acuto, che di norma associamo ad un suono più potente e presente (dopotutto, il tasto od il potenziometro “loudness” del nostro vecchio hi-fi, che serve a migliorare l’ascolto a bassi volumi, fa proprio quello: enfatizzare range basso ed acuto).

Le curve isofoniche sono in linea di principio alla base dei pesi che vengono utilizzati nella valutazione dell’impatto acustico. Spesso incontriamo la dicitura dB(A), o con altro indice, nell’indicazione di un livello decibel SPL. Ciò significa che ad un livello assoluto in dB SPL sono stati applicati fattori moltiplicativi che ne correggono il valore in funzione della frequenza, allo scopo di restituire un numero più indicativo del livello “percepito” che non di quello reale.
Diverse fonti sonore da 80dB(A) SPL potrebbero avere pressioni assolute molto diverse, ma avranno simili livelli di intensità percepita, indipendentemente dalla frequenza del suono in oggetto; ciò è utile ogni qualvolta sia importante determinare l’effetto di un suono sull’uomo o sull’ambiente (ad esempio, per valutare un impatto da inquinamento acustico) indipendentemente dal tipo di suono e dalla frequenza della fonte.
Un’ ultima chicca, prima di passare ad altro. Normalmente definiamo la prima curva dal basso, quella a 0 Phon, come soglia di udibilità. Questo per definizione (dopotutto, gli 0dB SPL indicano un livello alla soglia della percettibilità, come ricorderete senz’altro se avete diligentemente ripassato questo prima di cimentarvi nella lettura). Viceversa avremo l’ultima curva in alto che rappresenterà la soglia del dolore, e quindi il nostro limite fisiologico. Fra i due estremi, c’è il campo udibile, e questo può variare di molto da individuo ad individuo.
In particolare, in un soggetto anziano affetto dalla classica otosclerosi senile, la soglia di percettibilità tende ad alzarsi progressivamente, mentre quella del dolore rimane spesso invariata (quando non addirittura tende a scendere), traducendosi così in un notevole restringimento del range dinamico udibile.
Questo risponde definitivamente ed in modo scientificamente inoppugnabile ad una domanda che ha torturato giovani di ogni generazione, ovvero: perché diamine se parli a voce normale alla nonna non capisce un’acca, ma non appena imbracci la chitarra elettrica si ribalta sulla sedia a dondolo? Ora lo sapete, e potete porgerle le vostre scuse.
Come ormai di consueto, arriva il momento in cui il mio discorso (a proposito, tutto chiaro fin qui?) si sposta dal suono che pascola allegro per prati e valli, a quello che corre nei cavi dei nostri studi e diventa numeri binari nei nostri sistemi digitali, in un percorso che porta dritto all’ultimo singolo scaricato da iTunes sul vostro lettore.
Spesso il neofita confonde (e si confonde) nel passaggio fra un mondo e l’altro e viceversa. Sgomberiamo quindi subito il campo da dubbi ed incomprensioni.
Abbiamo finora parlato del livello di loudness che otteniamo in termini di pressione sonora e percezione, ed è quello che incrementiamo quando giriamo la manopola del volume sul nostro impianto d’ascolto, o pigiamo con più forza i tasti del nostro pianoforte.
Ma supponiamo di ascoltare la musica nella nostra automobile su un riproduttore di CD o mp3, senza toccare il volume. Materiale diverso, brani diversi, album ed artisti diversi, potrebbero avere (anzi, avranno senz’altro) differenze, anche rilevanti, di livello reale e di loudness percepito.
Qualcuno, anni fa, ha pensato che se la propria musica avesse avuto, a parità di condizioni d’ascolto, un livello (sia reale che percepito) maggiore di quello d’altri, l’ascoltatore avrebbe inconsciamente giudicato quella musica migliore delle altre.
Follia, direte voi… soprattutto alla luce del fatto che l’ascoltatore ha facoltà di alzare ed abbassare il volume a piacimento.
Vero. Eppure la cosa funzionò. Erano gli anni ’90, ed era scoppiata la loudness-war, ovvero una rincorsa a chi era (ed è tutt’oggi) più bravo a stipare nei limiti del range dinamico gestibili dal supporto digitale un livello assoluto (in termini di dBFS di picco ed RMS, e se non avete letto questo, so di essere noioso, è davvero ora di farlo), e di livello percepito (il loudness vero e proprio).
Quanti neofiti si sono chiesti “perché il mio CD registrato e mixato in cantina non suona forte quanto quello dei Coldplay?”.
Se ho una scatola di dimensioni standard e voglio riempirla con la maggior quantità di materia possibile, utilizzerò senz’altro una serie di accorgimenti, ad esempio:
-la riempirò fino all’orlo
-la riempirò in tutta la sua larghezza senza far montagne qua e là
-la riempirò possibilmente di oggetti cubici, e non di sfere (che lasciano spazi vuoti)
-la riempirò con oggetti dal massimo peso specifico possibile (ad esempio metallo piuttosto che sughero).
I principi su cui si basa la rincorsa al loudness sono molto simili.
–Riempirò la scatola fino all’orlo, ovvero utilizzerò tutto il range dinamico disponibile, normalizzando il picco del mio segnale a fondo scala (0dBFS, tralasciando per ora disquisizioni sul “true-peak” e l’intersampling, con le quali vi annoierò più avanti)
–Riempirò la scatola in tutta la sua larghezza, ovvero utilizzerò al meglio tutto lo spettro a mia disposizione
–Userò oggetti che lascino meno spazio vuoto possibile, ossia rincorrerò il massimo livello RMS possibile (e questo si ottiene riducendo il range dinamico, ovvero lo scarto fra massimo e minimo livello)
–Userò oggetti dal massimo peso specifico possibile, ovvero userò tecniche di incremento del loudness percepito a parità di livelli e range dinamico (ad esempio l’arricchimento armonico).
Questo è lo scenario in cui qualunque mastering-engineer deve combattere quotidianamente; perché, ebbene sì, è a lui che chiediamo di spremere il maggior loudness possibile dalla nostra musica, anche se spesso ci dimentichiamo che la musica l’abbiamo fatta noi (e se gli abbiam dato del sughero, difficile che la scatola arriverà a pesare come se fosse piena di ghisa).
Ad eccezione di questi spunti di riflessione, tuttavia, non è mia intenzione spingermi oltre nel giudizio di merito, perché lo scopo di quest’articolo è soprattutto quello di fornire una visione d’insieme degli aspetti tecnici correlati al loudness.
Indipendentemente dalle correnti di pensiero, quindi, andiamo a vedere come gestire e misurare il livello di loudness della musica che proponiamo al mondo, e quali sono i target a cui puntare, partendo da un po’di storia recentissima.
Se fino a pochi anni fa il livello di loudness di materiale sonoro registrato e trasmesso su supporto digitale era espresso perlopiù in termini di livello di picco ed RMS (in dBFS) mediato su porzioni più o meno lunghe di tempo, nel 2011 l’ITU (International Telecommunication Union) ha avvertito la necessità di introdurre parametri più aderenti al reale livello di loudness percepito, formalizzando un algoritmo di misura nel documento BS.1770-2.
Il proposito, indipendentemente dalle implicazioni tecniche che ne conseguono, è semplice: quello di poter fornire uno strumento per misurare e conseguentemente normalizzare (ovvero uniformare) il materiale audio in funzione del livello di loudness percepito, allo scopo (ad esempio) di non far saltare dalla sedia la nonna di cui al paragrafo precedente, quando inizia la pubblicità nel bel mezzo di Don Matteo.
O, in maniera implicita, quello di consentire a piattaforme di distribuzione digitale di contenuti multimediali (da iTunes a Spotify a YouTube…) di fornire continuità ed omogeneità nell’esperienza di ascolto di materiale molto eterogeneo.
E’stato così introdotto il concetto di LKFS, ovvero di Loudness K-weighted, relative to the Full Scale, poi recepito a livello internazionale come LUFS (Loudness Unit relative to the Full Scale) per pura necessità di rispettare le regole di nomenclatura internazionale convenzionali; indipendentemente dalla sigla utilizzata, comunque, ricordate che LUFS e LKFS significano la stessa cosa e sono di fatto termini intercambiabili (cfr. EBU R128 , nota 1, pag.3).
L’LKFS/LUFS è sostanzialmente un valore di livello logaritmico relativo alla Full-Scale digitale (esattamente come il dBFS), ed è imparentato piuttosto intimamente con il dBFS RMS, ad eccezione del fatto che:
– i valore di segnale sono pesati in frequenza (K-weighted) prima della media quadratica, applicando 2 stadi di filtrazione la cui sovrapposizione emula in modo significativamente accurato la risposta percettiva del sistema uditivo umano (vedi le curve isoPhon prima descritte):
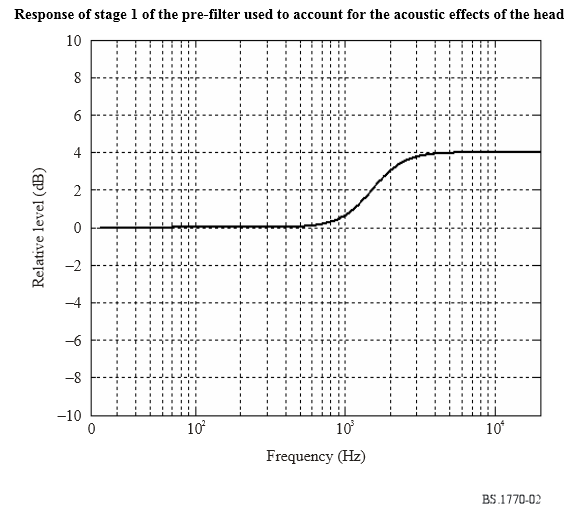

– la media quadratica (RMS) viene calcolata per ciascun canale audio (1 se mono, 2 se stereo, 5 se surround), ed i risultati di ciascun canale sono messi in sommatoria pesata
– i valori sono ulteriormente pesati in livello, suddividendo il tempo di misura in blocchi da 400ms parzialmente sovrapposti, sui quali viene applicato un gate differenziale su 2 livelli progressivi di soglia, prima di procedere all’integrazione dei valori.
Il livello complessivo di loudness è poi definito univocamente da tre parametri, il livello di picco (True Peak Level), il livello di Program loudness (il livello di loudness, in LKFS, integrato sull’intera durata del materiale audio, sia esso uno spot, un brano, una scena di un film) ed il Loudness range (ovvero come e di quanto il livello in LKFS varia nel tempo).
Aldilà della procedura che ho qui sintetizzato in modo approssimativo (chiunque voglia approfondire l’algoritmo di calcolo può farlo qui), il concetto fondamentale è che:
i LUFS/LKFS ci forniscono un parametro oggettivo per valutare il livello di loudness ottenuto nei nostri lavori, sia allo scopo di allinearli a valori standard, in funzione della loro destinazione d’uso, ma anche semplicemente al fine di crearci un nostro standard di lavoro, in modo da creare mix (se siamo produttori/mix-engineers) o master (se siamo mastering-engineers) omogenei fra loro in termini di loudness percepito.
Non solo, ma idealmente (anche se i tempi non sono ancora completamente maturi), la normalizzazione del loudness ci consente di guardare alla loudness-war in modo più rilassato (o di gridare alla fine della guerra, come alcuni han fatto all’uscita delle raccomandazioni di EBU ed ITU), laddove l’obiettivo non è più quello di far suonare il nostro CD più forte di quello del nostro “nemico”, ma semplicemente quello di far suonare bene la nostra musica ad un livello di LUFS standard per la piattaforma a cui è destinata.
Già, ma… Quali sono questi valori standard?
A questa domanda, gli enti normativi internazionali stanno rispondendo in modo via via più chiaro e definito, emanando linee guida e raccomandazioni specifiche per settore.
Le già citate linee guida EBU R128 dell’ European Broadcasting Union fissano i valori raccomandati per l’audio in broadcasting (trasmissione radio o tv), indicando un Program Loudness di -23.0LUFS, con una tolleranza di +/-1.0LUFS nel caso di trasmissioni in diretta, e +/-0.5LUFS in tutti gli altri casi. Il True peak viene fissato a -1dBTP.
Freschissima (19 ottobre 2014) è l’emissione del documento tecnico AES TD1004.1.15-10 “Recommendation for Loudness of Audio Streaming and Network File Playback”, dell’Audio Engineering Society, che specifica i valori raccomandati di loudness per i contenuti audio trasmessi via web in streaming o disponibili in download (podcasting), indicando un livello massimo di loudness (program, ovvero integrato sulla durata complessiva del materiale in oggetto) di -16LUFS (ed un minimo di -20), e specificando inoltre che il loudness short-term integrato sui 60 secondi non ecceda di oltre 5LUFS il valore massimo. Anche in questo caso iI True peak è fissato a -1dBTP.
Se (e come) i distributori di contenuti audio digitali via web si conformeranno a tali raccomandazioni è parzialmente prematuro dirlo, anche perché si tratta, appunto, di raccomandazioni, seppure autorevoli; ciò che è sicuro è che già oggi l’esigenza di uniformare il loudness non è affatto ignorata dai grandi “dispensatori” di multimedia; basti pensare agli strumenti MFIT di Apple, ed in particolare alla tecnologia SoundCheck che inserisce nei metadati del materiale audio informazioni sul livello di loudness (valutato con criteri assimilabili a quelli della BS.1770-2), che vengono poi utilizzate dai dispositivi di riproduzione per normalizzare materiale diverso conformandolo al livello standard adottato da iTunes (in questo caso ancora i -16.0LUFS).
Youtube, dal canto suo, anche se non in via ufficiale, normalizza l’audio dei video a -13.0LUFS, mentre Spotify a -11.0LUFS.
Insomma, i tempi non sono forse ancora maturi per una normalizzazione universale, ma già oggi possiamo trarre da tutto questo delle informazioni fondamentali: ad esempio che chiedere ad un mastering engineer di spremere -8.0LUFS da un album che distribuiremo su iTunes è assolutamente inutile, e non fa altro che “erodere” parecchi dB al nostro range dinamico, che potremmo invece sfruttare a tutto vantaggio della qualità dei nostri transienti.
Vi ho fatto venir voglia, se già non lo fate, di misurare il loudness di tutti i vostri lavori passati, presenti e futuri? 😉
Bene, in tal caso concludo questa panoramica indicandovi alcuni LUFS meters disponibili sul mercato (ma considerate che ne esistono e ne esisteranno sempre di più, quindi non mancate di cercare voi stessi quello che meglio corrisponde alle vostre esigenze ed il vostro budget):
Klangfreund LUFS Meter
HOFA 4U Meter
MeterPlugs LCAST
Melda MLoudness Analyzer
Waves WLM Plus

Quest’opera di Manuel Daniele è distribuita con Licenza Creative Commons Attribuzione – Non commerciale – Non opere derivate 3.0 Unported.

ciao
bellissimo articolo..
Grazie! 🙂
Sono felicissimo di sentir (leggere) parlare dell’argomento in italiano, specie se in modo così snello e con la giusta dose di goliardia che solo chi ne ha piena conoscenza può permettersi.
In giro per il web ce n’è abbastanza di articoli e discussioni varie ma tutti in inglese, così come il libro “Mastering Audio the art and the science” di Bob Katz che comprai alla Hoepli di Milano non mi è stato di grande aiuto, sempre per via della fatica che faccio per decifrarne i concetti, al punto che abbandonai l’approfondimento sui testi per intraprendere la strada dell’esperienza personale. Ed è proprio qui che scatta il cortocircuito cerebrale..
Analizzando con il Loudness Meter (meeter bridge di Izotope Ozone 5) i diversi brani che ho preso in esame (rock, metal e soprattutto elettronica dei nostri giorni di cui trovo appagante quel suono tanto ampio quanto compresso), sia da CD originali che da mp3 di varia provenienza, raramente si arriva sotto i -10LUFS integrati e -5LUFS momentari che corrispondono a circa -7.5 dB RMS. Eppure I-Tunes, della quale libreria è costituita in gran parte di programmi musicali dello stesso genere che nei pienissimi arrivano a sfoggiare spudoratamente valori RMS fino a -6dB, normalizza a -16LUFS.. Più che portare il fondo scala a -6dB buttando via metà dell’headroom digitale disponibile (che mi pare la cosa più stupida da fare) pur di acquietare a -16 brani che sui CD suonano a -10 non mi so dare altra spiegazione.. Se il broadcast radio FM comprime ulteriormente fino a TOT LUFS (-8? -7? non ho mai misurato e non so se esiste uno standard) I-Tunes che fa.. de-comprime?
Concludo quindi con una domanda: che senso ha normalizzare a valori inferiori di quelli nativi dei brani così come escono dagli studi di mastering?
spero di non aver posto una domanda del tutto sciocca, nel caso lo fosse sii clemente, Matteo
Ciao Matteo,
il senso di una normalizzazione “al ribasso” è quello di assicurarsi che in una playlist possano tranquillamente coesistere musica classica, jazz, pop, thrash-metal, dance e così via, senza discontinuità di volume percepito. Normalizzare verso l’alto brani di livello più basso implicherebbe una modifica dinamica sostanziale, comprimendo e/o limitando, che non è prevista, né tantomeno desiderata, evidentemente, da chi ha prodotto il brano. E’decisamente più facile abbassare il livello di ciò che è più alto della media.
Come giustamente osservi, prendere un brano con -6dBfs RMS e ridimensionarlo a -16LUFS significa di fatto vanificare la fatica fatta per stiparne la dinamica lassù, sempre più vicino agli 0dB… Ma siamo sicuri che ciò sia davvero un male? Non ci consente invece di produrre e finalizzare più serenamente, sfruttando meglio il nostro range dinamico, e lasciandoci finalmente alle spalle l’affanno di rincorrere il massimo livello possibile, sacrificando per questo anche la qualità oggettiva del risultato finale? 🙂
Non so.. la faccenda mi lascia del tutto perplesso. Ciò non fa altro che rinforzare il mio ODIO più assoluto verso il pianeta Apple governato da quel pensiero monopolista e totalitario degno di un regime dittatoriale. I-Tunes dovrebbe limitarsi a distribuire musica su scala mondiale, che è già mostruoso (43 milioni di titoli!!!) oltre a questo vogliono pure dettare gli standard.
Non oso immaginare la forma d’onda di un mix fatto con Tchaikovsky e con Skrillex entrambi appassionatamente a -16LUFS.. maestosi picchi fino al Fondo Scala e morbide valli che sprofondano nel rumore di fondo contro una striscia unica normalizzata a -6dB.
Nonostante la normalizzazione gentlmente appioppata da Apple Tchaikovsky manterrà comunque il suo estesissimo LU range di decine di dB mentre l’altro ne avrà 5 o 6 al massimo nel suo brano più ispirato. Che sti due pezzi così diversi condividano lo stesso valore LUFS nel lungo termine, secondo me, ha poco o niente senso. La classica e la lirica rispetta la naturale dinamica degli strumenti (anche 80dB) e da il suo massimo nelle sale concerto e negli impianti High-End mentre l’elettronica nasce per suonare forte nelle discoteche costringendo ad un forte loudness anche a chi ha i timpani cementificati da ore di SPL estremi e per infastidire il prossimo sugli autobus tramite gli altoparlantini degli smartphone, il rock e il metal invocano il “muro” del suono (wall of sound) nei concerti e sugli impianti domestici di fascia medio-bassa. Chi oggi vuole utilizzare un algoritmo così raffinato come il BS-1770 per unificare questi mondi così diversi per me è soltanto un bieco dittatore che vuole sfruttare a suo vantaggio l’enorme buco diplomatico lasciato da una guerra persa (mi riferisco alla loudness war) per espandere il suo impero.
Non ho mai comprato (e mai comprerò) musica da I-Tunes, ma se fossi un DJ avrei a che fare con tracce dubstep/drum’n bass normalizzate a -16LUFS che avrebbero anche -6 di picco? Dovessi mixarle poi con tracce da cd normalizzate a -0.01 bestemmierei nel microfono dell’MC !!
Spero vivamente che con questo si stiano tirando l’ennesima zappata sui piedi dopo l’i-watch e l’i-phone6.
Matteo
P.s.:ce l’hai un altro contatto oltre questo?
L’anomalia non è la normalizzazione, che dal punto di vista tecnico è un concetto sempre esistito e decisamente sano. Apple, che possa far simpatia o no, non ha fatto null’altro che adeguarsi a ciò che si fa da sempre nel broadcasting, nelle trasmissioni radio e tv, ed ha anzi anticipato un’esigenza comune per quanto riguarda lo streaming e la distribuzione digitale (esigenza che si è in effetti concretizzata con la AES TD.1004). Era semmai un’anomalia l’assenza totale di criteri, buone pratiche e linee guida in ambito digitale (dall’avvento del CD in poi).
Attenzione a non farti confondere le idee, le raccomandazioni sul loudness non hanno velleità di dettar legge su ciò che è il range dinamico, ed è ovvio che generi diversi richiedono utilizzi diversi della dinamica; la normazione si limita a collocare il livello di volume percepito (quello che normalmente si imposta smanettando sul volume del proprio sistema d’ascolto) in una fascia standard che consenta un’esperienza di continuità d’ascolto confortevole, indipendente dal genere. Lo scopo è di prevenire fenomeni che non hanno alcun vantaggio, se non procurare fastidio all’ascoltatore. Se una réclame televisiva ha per colonna l’aria sulla quarta corda di Bach, e quella successiva un brano degli SlipKnot, non è comunque una buona ragione per non sentire un’acca sulla prima pubblicità e cadere dalla sedia sulla seconda.
Idem, se ho una playlist in auto con un brano acustico di James Taylor seguita da un pezzo degli AC/DC. Cosa sgradevole che accade anche se dopo un CD di musica classica carico un CD di musica techno: se non mi ricordo di abbassare il volume, molto probabilmente esco di strada non appena parte il secondo album.
Tutto ciò è assolutamente indipendente dalla mia scelta di poter alzare il volume a palla quando ascolto heavy-metal e tenerlo moderato quando ascolto jazz.
Da addetto ai lavori, trovo molto più dittatoriale la necessità di schiantare la dinamica di un brano per ottenere un RMS su CD equiparabile (o possibilmente superiore) a quello di un concorrente, sacrificando tutto il resto, anziché costruire una gain-structure corretta ed un impatto dinamico così come realmente vorrei che fosse.
La normalizzazione del loudness dell’audio digitale, che ti piaccia o no, è stata salutata da produttori, mixing e mastering engineers come la fine di un incubo! 🙂
Se vuoi puoi contattarmi tranquillamente via messaggio su facebook (https://www.facebook.com/Fonderiefoniche), mi fa senz’altro piacere 🙂
Pingback: I decibel spiegati a mia figlia… – fonderiefoniche